- 2023-10-05: Introduction to Python
- 2023-10-12: Class cancelled
- 2023-10-19: Introduction to Python, cont.
- 2023-10-26: Introduction to Python, cont.
- 2023-11-09: Introduction to Python, cont.
- 2023-11-16: Introduction to Python, cont.
- Napisz funkcję, która zapyta użytkownika o liczby x i y, a następnie obliczy działanie:
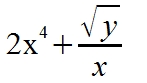
- Napisz funkcję, w której zdefiniujesz jakieś hasło, a kiedy hasło zostanie wpisane, program wydrukuje 'Doskonale!' (Skorzystaj z pętli 'while'.)
Przykładowe działanie programu:Podaj hasło: jajko Podaj hasło: 123abc Podaj hasło: Kasia Podaj hasło: Angelina Doskonale!
- Napisz funkcję, która zapyta użytkownika w pętli 'for' trzy razy o podanie liczby, a następnie wydrukuje pierwiastki tych liczb z dokładnością do trzech miejsc po przecinku.
Przykładowe działanie programu:pierwiastki_liczb() Podaj liczbę: Pierwiastek liczby 4 wynosi 2.000. Podaj liczbę: 10 Pierwiastek liczby 10 wynosi 3.162. Podaj liczbę: 16 Pierwiastek liczby 16 wynosi 4.000.
- Stwórz funkcję, która zapyta użytkownika o to, jaki jest dzisiaj dzień. Następnie zapyta, która jest godzina. Na koniec wydrukuje stosowny komunikat, np. Dzisiaj jest czwartek, godzina 10:30. Skorzystaj z formatu drukowania %s.
- Stwórz tablicę z imionami, a następnie wydrukuj elementy tablicy w tym formacie:
0 => Basia 1 => Maciej 2 => Andżela 3 => Piotr
Skorzystaj z funkcji 'enumerate'.
- Napisz funkcję, która zapyta użytkownika o liczby x i y, a następnie obliczy działanie:
- Napisz funkcję, w której zapytasz użytkownika o tekst oraz liczbę. Następnie sprawdź czy litera 'a' wystąpiła w podanym tekście przynajmiej tyle razy, ile podał użytkownik. Jeśli tak, wydrukuj komunikat: 'Tekst spełnia wymagania.' Jeśli nie, to wydrukuj: 'Ale pech. Spróbuj jeszcze raz.'
>>> sprawdzaj() Podaj tekst: salamandra Podaj liczbę: 3 Tekst spełnia wymagania.
Instrukcja instalacji narzędzi
1. Ściągnij Python, wersja 3.12.0 dla systemu 32-bit lub 64-bit.
2. Zainstaluj python-3.12.0.exe (32-bit) lub python-3.12.0-amd64.exe (64-bit).
3. Otwórz IDLE (Python) z menu programów.
4. Przywitaj się ze światem komendą: print ('Hello world!')
5. W oknie Python Shell idź do File -> Save As i skopiuj ścieżkę, w której jest plik python.exe.
Np. C:\Users\jbach\AppData\Local\Programs\Python\Python312-64
6. W polu z lupą na pasku narzędzi w Windows 10 wyszukaj "Uruchom" i wpisz "cmd". Otworzy się okno z wierszem poleceń.
7. W oknie wpisz "cd", a po spacji wklej ścieżkę, którą skopiowałeś w punkcie 4. Np. cała komenda będzie wyglądała tak:
cd C:\Users\jbach\AppData\Local\Programs\Python\Python312-64
Zatwierdź komendę, klikając ENTER.
Polecenie powyżej przenosi do katalogu, w którym jest plik python.exe. Możesz go zobaczyć, wpisując dir i zatwierdzając przez kliknięcie na ENTER.
8. Zainstaluj pip komendą: python -m pip install --upgrade pip. Jeżeli masz problemy z instalacją 'pip', spróbuj rozwiązać je, korzystając z TEJ strony.
9. Zainstaluj nltk komendą: python -m pip install nltk
10. Zainstaluj matplotlib komendą: python -m pip install -U matplotlib
11. Zainstaluj numpy komendą: python -m pip install -U numpy
12. Otwórz ponownie IDLE (Python) z menu programów.
13. Zaimportuj nltk komendą: import nltk
14. Ściągnij korpusy i narzędzia do NLTK komendą: nltk.download()
Pojawi się okno, z którego wybierz "Everything used in the NLTK Book" i kliknij "Download".
15. Jeżeli nie pojawiły się błędy podczas pobierania danych, to możesz przetestować, czy wszystko jest w porządku komendą:
from nltk.book import *
Powinien pojawić się niebieski tekst:
*** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: 'texts()' or 'sents()' to list the materials. text1: Moby Dick by Herman Melville 1851 text2: Sense and Sensibility by Jane Austen 1811 text3: The Book of Genesis text4: Inaugural Address Corpus text5: Chat Corpus text6: Monty Python and the Holy Grail text7: Wall Street Journal text8: Personals Corpus text9: The Man Who Was Thursday by G . K . Chesterton 1908
16. Przetestuj, czy masz pakiety Matplotlib i NumPy komendą:
text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
Jeżeli pojawił się wykres rozproszenia, to Python i NLTK są poprawnie zainstalowane. Gratulacje!
Homework: Do again at home the tasks from section 1 and section 2 which were presented in class and check if your Python and nltk settings are working on your computer at home.
Exercises with frequency distribution.
Homework: Do the exercises 1-12 at the end of Chapter 1.
# 1) Dla text3 wydrukuj 5 pierwszych najczęściej występujących wyrazów w formacie:
# wyraz *** ilość
# 2) Wydrukuj wyrazy, które mają 11 znaków wraz z informacją o ilości występowania w formacie:
# ilość %%% wyraz
# 3) Wydrukuj wyrazy, które zaczynają się od "G" - też z informacją, ile razy wystąpiły.
# wyraz => ilość
# 4) Zsumuj za pomocą listy frekwencyjnej wszystkie wyrazy z text3.
# 44764
# => 44764
# 5) Zsumuj ilość wystąpień tylko tych wyrazów, które zaczynają się od "G", korzystając z listy frekwencyjnej.
http://bachan.speechlabs.pl/files/New_York_Times.zip
Zadanie 1: Załaduj korpus New_York_Times.
Zadanie 2: Wydrukuj nazwy plików w tym korpusie.
Zadanie 3: Zbuduj konkordans dla wyrazu 'sisters' w pliku 1.
Zadanie 4: Wydrukuj tylko te wyrazy z pliku 1, które są pisane wielkimi literami, np. BROOKS.
Zadanie 5: Policz, ile jest zdań w pliku 2.
Zadanie 6: Wydrukuj 60 pierwszych znaków z pliku 3.
>> Zadanie 7: Dodaj plik tekstowy do korpusu New_York_Times z listą wyrazową (bez polskich znaków). Wydrukuj najdłuższy wyraz z tego pliku.
Zadanie 1: Ściągnij, rozpakuj i załaduj korpus do nltk.
Zadanie 2: Wydrukuj nazwy plików w tym korpusie.
Zadanie 3: Zbuduj konkordans dla wyrazu 'Brexit' w pliku Times_file_01.txt.
Zadanie 4: Znormalizuj tekst z pliku Times_file_01.txt do małych liter i oblicz, ile jest typów wyrazów.
Zadanie 5: Stwórz listę frekwencyjną wyrazów z pliku Times_file_01.txt. Następnie wydrukuj tylko te wyrazy, które pojawiły się 4 lub więcej razy. Wyświetl wyraz i liczbę wystąpień tego wyrazu w formacie: wyraz <=> liczba.
Zadanie 6: Wydrukuj najkrótsze zdanie (lub zdania) z pliku Times_file_02.txt.
Zadanie 7: Wydrukuj cyfry (nie liczby!) w pliku Times_file_03.txt.
Zadanie 8: Zsumuj cyfry z zadania 7.
Zadanie 9: Napisz funkcję, w której zapytasz użytkownika o imię oraz ilość wykonanych zadań. Jeżeli liczba jest większa od 3, to wydrukuj informację 'imię, bardzo dobrze!.', a jeśli nie to wydrukuj 'imię, musisz więcej pracować w domu.' => Za 'imię' należy podstawić to, co wpisał użytkownik, czyli np. 'Jola, bardzo dobrze!' lub 'Jola, musisz więcej pracować w domu.'
Zadanie 10: Napisz funkcję, która zapyta użytkownika o liczby x i y, a następnie obliczy działanie:
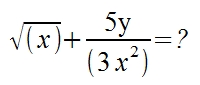
Zadanie 11: Napisz funkcję, która zapyta użytkownika w pętli 'for' trzy razy o podanie liczby, a następnie wydrukuje sześciany tych liczb.
Przykładowe działanie programu:
>>> szesciany_liczb() Podaj liczbę: 3 Sześcian liczby 3 wynosi 27. Podaj liczbę: 5 Sześcian liczby 5 wynosi 125. Podaj liczbę: 4 Sześcian liczby 4 wynosi 64.
1. Ściągnij, rozpakuj i załaduj korpus do nltk. Korpus znajduje się tutaj: http://bachan.speechlabs.pl/files/Corpus_test1_A.zip
2. Wydrukuj nazwy plików w tym korpusie.
3. Zbuduj konkordans dla wyrazu „Sala” w pliku paper1.txt.
4. Wydrukuj tylko te wyrazy z pliku paper1.txt, które mają 10 liter.
5. Wydrukuj tylko te wyrazy z pliku paper1.txt, które mają ciąg liter „ff”.
6. Stwórz listę frekwencyjną wyrazów z pliku paper1.txt. Następnie wydrukuj tylko te wyrazy i tokeny, które pojawiły więcej niż 3 razy w tekście. Wyświetl wyraz i liczbę wystąpień tego wyrazu/tokenu w formacie: wyraz *** >>> *** liczba.
7. Policz, ile jest różnych typów znaków w pliku paper2.txt.
8. Wydrukuj tylko duże litery z pliku paper2.txt.
9. Wydrukuj 21 ostatnich znaków z pliku paper2.txt.
10. Policz, ile jest zdań w pliku paper3.txt.
11. Skonkatenuj dwa pierwsze wyrazy dwóch pierwszych zdań z pliku paper3.txt, aby powstał tekst „EmilianoJames”.
12. Wydrukuj najdłuższe zdanie z pliku paper3.txt.
13. Wydrukuj drugi wyraz z ostatniego zdania z pliku paper3.txt.
14. Napisz funkcję, która zapyta użytkownika o liczby x i y, a następnie obliczy działanie:
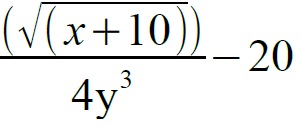
15. Napisz funkcję, która zapyta użytkownika o Twoje ulubione danie oraz jak często jesz to danie. Jeśli jesz to danie cztery razy w tygodniu lub więcej, to wydrukuj komunikat: „Ty naprawdę kochasz DANIE!”. Jeśli jesz to danie rzadziej, to wydrukuj komunikat: „DANIE to dobre danie, ale nie najlepsze.” Za DANIE podstaw tekst, który wpisałeś/-aś, korzystając z operatora %s.
Warunki zaliczenia semestru letniego 2024
Download: exercises in ODT format, PDF format, DOS-exercises.zip folder.
- cd - shows the present working directory/folder (pwd command in Linux)
- tree /f - shows a tree structure of directory/folder
- type - shows the content of a file, e.g. type file01.txt
- dir *part_of_filename* /s => finds files which contain given text in the filename. In the example below, the command looks for the word 'encoding' in the filename.
/s => tells the dir command to search the current directory and all sub directories.
C:\Users\Jola\Documents\Teaching>dir *encoding* /s.
Wolumin w stacji C to OS Numer seryjny woluminu: 982B-4B29 Katalog: C:\Users\Jola\Documents\Teaching\Teaching2013_2014\Systemy_pisma 2013-10-23 17:31 16 200 2013-10-17_encoding_systems.odp 2013-10-23 17:31 90 664 2013-10-17_encoding_systems.pdf 2 plik(ów) 106 864 bajtów Katalog: C:\Users\Jola\Documents\Teaching\Teaching2015_2016\Systemy_pisma 2015-10-22 12:40 16 310 2015-10-15_encoding_systems.odp 2015-10-22 12:40 122 425 2015-10-15_encoding_systems.pdf 2 plik(ów) 138 735 bajtów Razem wymienionych plików: 4 plik(ów) 245 599 bajtów 0 katalog(ów) 3 477 344 256 bajtów wolnych - findstr => finds a given string (text) in a certain text file or any file.
- In the 1st example, the word "echo" is looked for in the file 'DOS-exercises.txt'
C:\Users\Jola\Documents\Teaching\>findstr "echo" Dos-exercises.txt - In the 2nd example, the word "Jola" is looked for in any text file with the .txt extension.
C:\Users\Jola\Documents\Teaching\>findstr "Jola" *.txt new_file.txt:Jola ma kota. test.txt:Jola ma kota
- In the 1st example, the word "echo" is looked for in the file 'DOS-exercises.txt'
- xcopy /s - copy the content of the folder with the subfolders. In the example, copy folder: '2015-10-22-DOS' to 'here' marked by the dot '.' 'Here' in the example is the Desktop: 'C:\Users\Jola\Desktop'
C:\Users\Jola\Desktop>xcopy /s c:\Users\Jola\Documents\Teaching\Teaching2015_2016\Jezyki_skryptowe\2015-10-22-DOS . - mkdir - creates a new directory/folder
c:\Users\Jola\Documents\Teaching\Teaching2017_2018\Jezyki_skryptowe\2018-03-01>mkdir EXERCISESc:\Users\Jola\Documents\Teaching\Teaching2017_2018\Jezyki_skryptowe\2018-03-01>dir Wolumin w stacji C to OS Numer seryjny woluminu: 982B-4B29 Katalog: c:\Users\Jola\Documents\Teaching\Teaching2017_2018\Jezyki_skryptowe\2018-03-01 2018-03-01 10:50 <DIR> . 2018-03-01 10:50 <DIR> .. 2018-03-01 10:46 274 2018-03-01_exercises.txt 2018-03-01 09:51 <DIR> DOS-exercises 2018-03-01 09:50 115 465 DOS-exercises.pdf 2018-03-01 09:50 39 682 DOS-exercises.zip 2018-03-01 10:50 <DIR> EXERCISES 3 plik(ów) 155 421 bajtów 4 katalog(ów) 1 368 072 192 bajtów wolnych - rmdir - removes a directory/folder
- rmdir /s - removes a directory/folder with subdirectories
Substitute commands for Linux: Windows vs. Linux
- cd <=> pwd (present working directory)
- dir <=> ls (list directory)
- type <=> cat
- copy con <=> touch
- move <=> mv
- copy <=> cp
- del <=> rm
- tree <=> ls -R
- find <=> grep
Ćwiczenia:
1. Wydrukuj wszystkie pliki PDF, które są na Pulpicie.
2. Stwórz nowy folder w swoich dokumentach za pomocą funkcji "mkdir".
3. Skopiuj wszystkie pliki PDF z Pulpitu do nowego folderu w swoim nowo powstałym folderze.
4. Wydrukuj tylko te pliki z Pulpitu, które zawierają wyraz "Praat".
Homework: Do the exercise 6, 7, 24 and 25 at the end of Chapter 3.
File operations: reading files and writing to files
Treść zadania, które było wykonane w klasie:
# 1 - Stwórz plik tekstowy z danymi.
# 2 - Poproś użytkownika o podanie nazwy pliku, który chce przeszukać.
# 3 - Zapytaj użytkownika, jakiego znaku poszukuje.
# 4 - Zapytaj użytkownika, na jaki znak zamienić szukany znak.
# 5 - Przeszukaj plik i policz, ile razy szukany znak wystąpić w pliku
# oraz zamień go zgodnie z życzeniem użytkownika.
# 6 - Tekst ze zamienionymi znakami wydrukuj do pliku zewnętrznego 'output.txt'.
# 7 - Wydrukuj liczbę wskazanych znaków na ekran.
Homework: Do the following tasks.
-
1 - Poproś użytkownika o podanie liczb a i h, aby obliczyć pole trójkąta (a, h).
2 - Oblicz pole i wydrukuj wyniki na pliku zewnętrzenego.
3 - Powtórz te obliczenia trzy razy z innymi danymi (stwórz pętlę for). -
1 - Wczytaj plik tekstowy, który ma trzy kolumny: (1) imię, (2) nazwisko rodowe, (3) nazwisko
2 - Pobierz nazwiska z trzeciej kolumny i użyj w pytaniu, np.: "Jak się masz, Tomaszczyk?"
3 - Do pliku zewnętrzego wydrukuj nazwiska z trzeciej kolumny oraz odpowiedź użytkownika.Format plik wejściowego:
Joanna Krzyżanowska Tomaszczyk Tomasz Górski Górski Marcelina Nowak Kowalska
Format plik wyjściowego:
Tomaszczyk dobrze Górski źle Kowalska świetnie
Tekst do zadania "foreign":
Foreign is a afafafa word. I like foreign films. Who is forrein in this fantastic class? Foreing is not spelled this way. Foren languages are my passion.
Tekst do zadania "phones":
Telephones are everywhere nowadays. One can't imagine life without a mobilephone. Mobilephones connect people and make us feel closer. I posses three phones myself.
- Wydrukuj do pliku zewnętrzenego "output.txt" w folderze "2024-06-13" swoje imię z literami jedną pod drugą (w pętli "for"). Następnie zapytaj użytkownika o jakąś liczbę i dodaj do niej 20. Wydrukuj sumę do tego samego pliku.
- Stwórz listę z poniższymi wyrazami:
programming, Python, prgrming, python, Programing, to program
Napisz wyrażenie regularne, które znajdzie różne warianty wyrazu "programming". Skorzystaj z re_show i pętli "for".
- Masz dany tekst:
I have television. teleWizor I like my TeeeeleWizor, and I have many tlviiiiisions
Napisz wyrażenie regularne, które odpowiada różnym pisowniom wyrazu "telewizor". Policz, ile jest tych wyrazów.
Przykładowe działanie programu:['television', 'teleWizor', 'TeeeeleWizor', 'tlviiiiisions'] The word 'telewizor was found 4 times.
- Wczytaj plik tekstowy, który zawiera poniższy tekst. Policz, ile jest wierszy w pliku. Zamień partykułę "nie" na "tak" i wydrukuj zmieniony tekst na ekran.
Ja nie mam ochoty. Zapomnienie. Co to, to nie. Nie ma mnie. Niezmiernie niezadowolony człowiek nie ma czasu na wniesienie walizek.
- Wydrukuj indeksy (miejsce występowania) partykuły "nie" z pliku z zadania 4. Najpierw przeprowadź tokenizację:
['Ja', 'nie', 'mam', 'ochoty', '.', 'Zapomnienie', '.', 'Co', 'to', ',', 'to', 'nie', '.', 'Nie', 'ma', 'mnie', '.']
W pętli "for" z funkcją enumerate, wskaż indeksy partykuły "nie".
1 11 13
- Wczytaj plik tekstowy "text_for_taks6_0.txt" i wydrukuj trzecią linijkę oraz jej długość.
- Zsumuj w pętli "for" liczby od 5 do 10 i wydrukuj sumę do pliku zewnętrznego "suma.txt"
- Stwórz plik z listą wyrazów (poza Pythonem). Znajdź najdłuższy wyraz w tym pliku.
- 1 – Ściągnij i wczytaj plik chairman.txt. Plik znajduje się tutaj: http://bachan.speechlabs.pl/files/chairman.txt
2 - Za pomocą funkcji re_show znajdź rożne pisownie wyrazu "chairman".
3 – Znajdź wszystkie liczby w pliku i wydrukuj.
4 – Policz, ile jest wszystkich wyrazów/tokenów w pliku.
Przykładowe działanie programu:Poznan, 2018-05-24 Task 1 I am wondering about a word {chairman} at least 6 times. Can a woman be a {Chairman}? Maybe it is better to say a chairperson? {Chairrrrrmannnn}!!! Does it sound very masculine? Even if I say this 1000 times for me it is neutral. I would say {charman} may also be a woman. And what do you think about the word '{chaiman}'? ['2018', '05', '24', '1', '6', '1000'] 77 - 1 – Wczytaj plik pandemic_0.txt, który zawiera następujący tekst:
What a tragedy! 2020 is a totally different year because of the viiiirus. Who could predict in 2019 that in 2020 students in many countries will take online tests because of pandemic of Covid-19?! The other name of this deadly Vairuuuuus is SARS-Cov-2. I hate this viiirs!
2 – Napisz wyrażenie regularne, które znajdzie wszystkie formy zapisu wyrazu „virus”. Wydrukuj te wyrazy. → Są 3 wyrazy „virus”: viiiirus, Vairuuuuus, viiirs.
3 – Policz i wydrukuj, ile jest wyrazów „virus” zapisanych w różny sposób w pliku.
4 - Policz, ile jest różnych typów wyrazów. Wydrukuj posortowane wyrazy unikatowe na ekran oraz ich liczbę.
5 – Napisz wyrażenie regularne, które znajdzie wszystkie wyrazy/tokeny, które zawierają
same cyfry albo kombinację liter, myślników i cyfr. Zamień te tokeny na „XXXX” i wydrukuj zmieniony tekst na ekran. Poprawnie zamieniony tekst powinien wyglądać tak :
What a tragedy! XXXX is a totally different year because of the viiiirus. Who could predict in XXXX that in XXXX students in many countries will take online tests because of pandemic of XXXX?! The other name of this deadly Vairuuuuus is XXXX. I hate this viiirs! - 1 – Zapytaj użytkownika o 5 liczb i stwórz z nich listę z liczbami.
2 – W pętli for zsumuj te liczby i wydrukuj sumę na ekran.
3 – Zapytaj użytkownika o podanie nazwy pliku.
4 – Utwórz plik o nazwie podanej przez użytkownika w punkcie 3.
5 – Wydrukuj do tego pliku sumę liczb.